Hybrid Pipeline Overview
Three-Stage Generation Process (S → D → G)
We sculpt high-fidelity synthetic data first, then use it to translate real-world clear frames into adverse conditions:
-
S – Simulation:
CARLA
CARLA: Open-source autonomous driving
simulator providing high-fidelity synthetic images with
pixel-perfect labels.
Visit CARLA → renders pixel-perfect clear/adverse pairs with full annotations. -
D – Diffusion:
Stable Diffusion
Stable Diffusion: Latent diffusion model for
high-detail image synthesis.
Learn more → / ALDM ALDM: Adaptive Latent Diffusion Model that refines realism using segmentation guidance.
View ALDM paper → boosts realism, guided by segmentation masks. -
G – GAN Adaptation:
DA-UNIT
DA-UNIT: Domain Adaptation with Unsupervised
Image-to-Image Translation Networks.
View paper → learns on the curated S + D pairs plus a 10% mix of real ACDC-Clear ACDC-Clear: Subset of the Adverse Conditions Dataset containing clear-weather driving images.
Visit ACDC → frames.
Inference: Feed any clear ACDC frame → DA-UNIT returns a photorealistic fog, rain, or night image with labels preserved.
Enhanced DA-UNIT Architecture
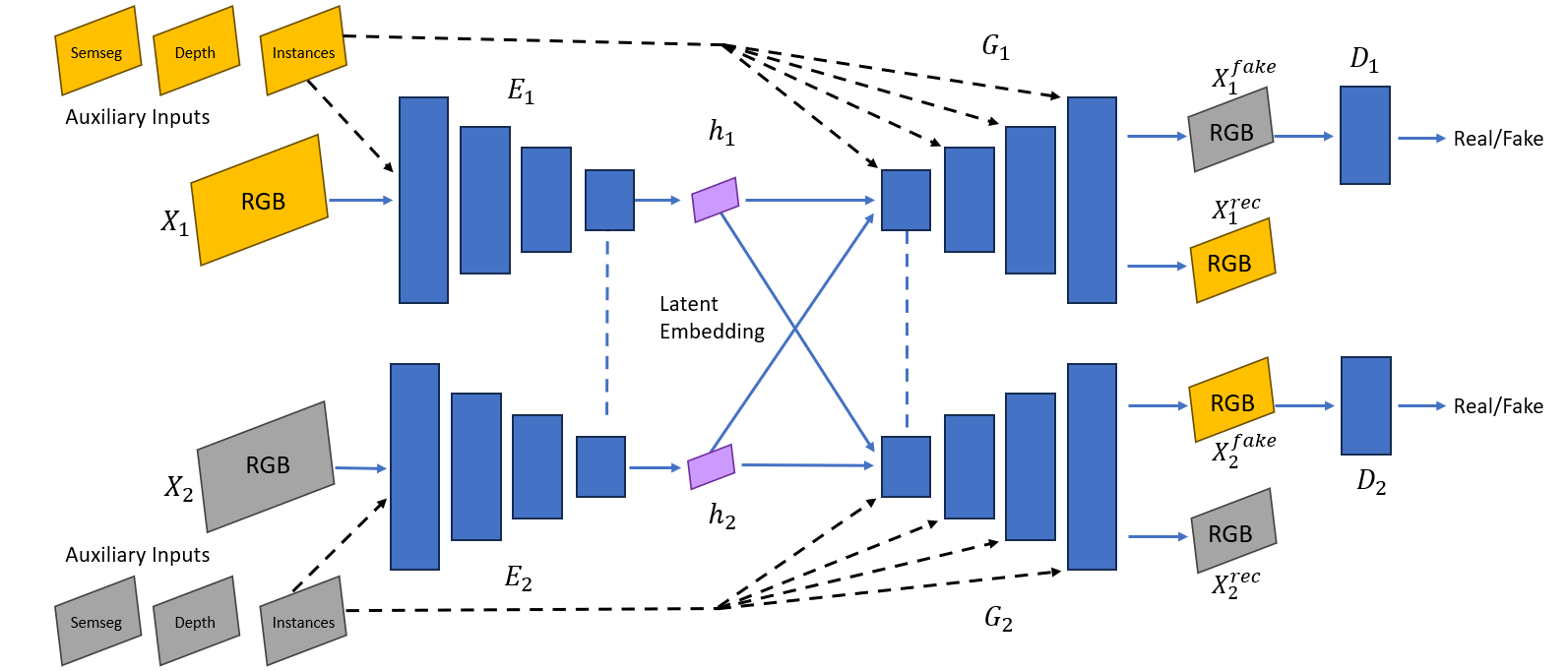
Key Architectural Improvements
- Support for depth, semantic, and instance data at encoder/decoder stages
- Improved object shape preservation through auxiliary inputs
- Enhanced label alignment with ground-truth data
- Novel training strategy combining simulated and real images
Technical Details
Blending Technique
Our novel blending approach addresses key challenges in the generation process:
- Adaptive merging of diffusion output with original simulated images
- Mitigation of artifacts (e.g., distorted vehicles)
- Preservation of photorealistic enhancements (e.g., wet roads, nighttime lighting)
Training Strategy
The enhanced training process combines multiple data sources:
- Simulation images for perfect pixel-level matching
- Unlabeled real images to close the simulation-to-real gap
- Auxiliary inputs (depth, semantic segmentation) for improved guidance
Performance Results
Performance highlights (ACDC):
- 78.57 % mIoU on ACDC-Adverse (test) — obtained with zero adverse-weather images in training.
-
+1.85 % mIoU on ACDC (val) overall,
versus the baseline
(
REIN
REIN: Robust Enhancement via Instance
Normalization pre-trained on Cityscapes and fine-tuned on
ACDC-Clear.
View Paper → pre-trained on Cityscapes → finetuned on ACDC-Clear ) . - Night subset: +4.62 % mIoU on ACDC-Night (val) over the same baseline.
Applications
Practical Benefits
- Cost-effective generation of adverse-condition training data
- Significant reduction in real-world data collection needs
- Improved robustness of autonomous perception systems
- Flexible adaptation to various adverse conditions (night, rain, fog, snow)


