Research Insights
After showing that SDG-DA can generate fog, rain, snow, and night scenes without any real adverse-weather examples, we distilled four core insights that explain how and why our pipeline works—and how you can leverage it immediately.
Major Findings
- Zero-Shot Performance: Our pipeline generates photorealistic adverse-condition images that boost semantic segmentation to 78.57% mIoU on ACDC-all without using any real adverse-weather training data.
- Simulation-to-Real Gap: Combining CARLA simulation with diffusion models bridges the synthetic→real domain gap.
- Label Preservation: Enhanced DA-UNIT preserves pixel-perfect semantic labels while generating photorealistic fog, rain, snow, and night.
- Data Reusability: Generated adverse-condition images are task-agnostic—use them for detection, segmentation, or any vision task.
- Operational Efficiency: Our pipeline drastically reduces costly real-world adverse-data collection and labeling.
Key Research Discoveries
Size Distribution Challenges
We were surprised to find that detection AP on certain ACDC adverse-weather splits (e.g. fog) actually exceeded the score on clear-weather images—despite the harsher conditions (lower visibility).
A closer look at object-size distributions revealed the reason: adverse scenes are dominated by larger, easier detect objects, while clear scenes contain a much higher share of small, difficult instances. This small-object bias in the "easy" clear data explains why the models performs better on some adverse splits.
This insight helped us optimize our pipeline to better handle the full range of object sizes, improving overall robustness across all weather conditions.
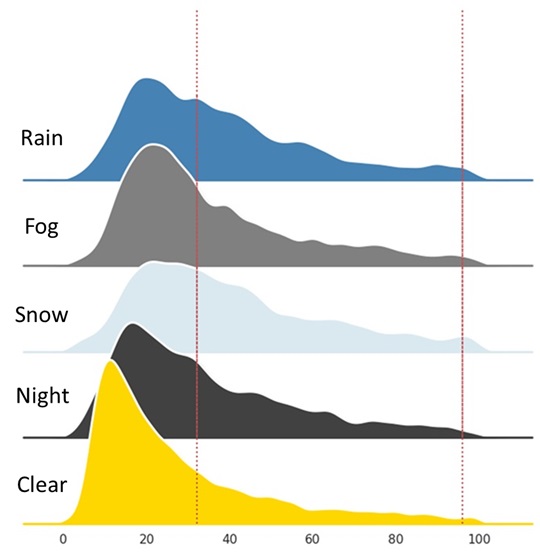
Figure: Distribution of object sizes (√area) across different weather conditions. Clear weather (yellow) has significantly more small objects than adverse conditions.
Cross-Weather Transfer
We trained on a single adverse condition and evaluated across all others. Below is our real-data credit-assignment table: the best in each column is bolded and the row headers highlight which split was used.
| Evaluated On | |||||||
|---|---|---|---|---|---|---|---|
| Trained On | Fog | Rain | Night | Snow | Clear | Adverse | All |
| ACDC-clear + Fog | 44.60 | 31.86 | 21.76 | 39.78 | 32.31 | 33.69 | 33.28 |
| ACDC-clear + Rain | 51.06 | 35.86 | 21.53 | 40.96 | 31.68 | 36.29 | 34.61 |
| ACDC-clear + Night | 46.15 | 32.36 | 24.50 | 37.44 | 32.02 | 34.09 | 33.51 |
| ACDC-clear + Snow | 51.35 | 34.18 | 21.78 | 44.48 | 31.86 | 35.33 | 33.73 |
| ACDC-clear + All | 53.02 | 36.14 | 25.59 | 47.02 | 32.31 | 39.05 | 36.43 |
This reveals that training exclusively on any single weather
condition does not guarantee the best performance on that same
condition—models trained on other splits can actually outperform
the "matched" model when evaluated under the same scenario.
Object Category Distribution
Different weather conditions introduce different category biases— here's a breakdown of how objects are distributed. Notice how clear vs. nighttime scenes contain proportionally more small, vulnerable categories (bicycles, motorcycles).
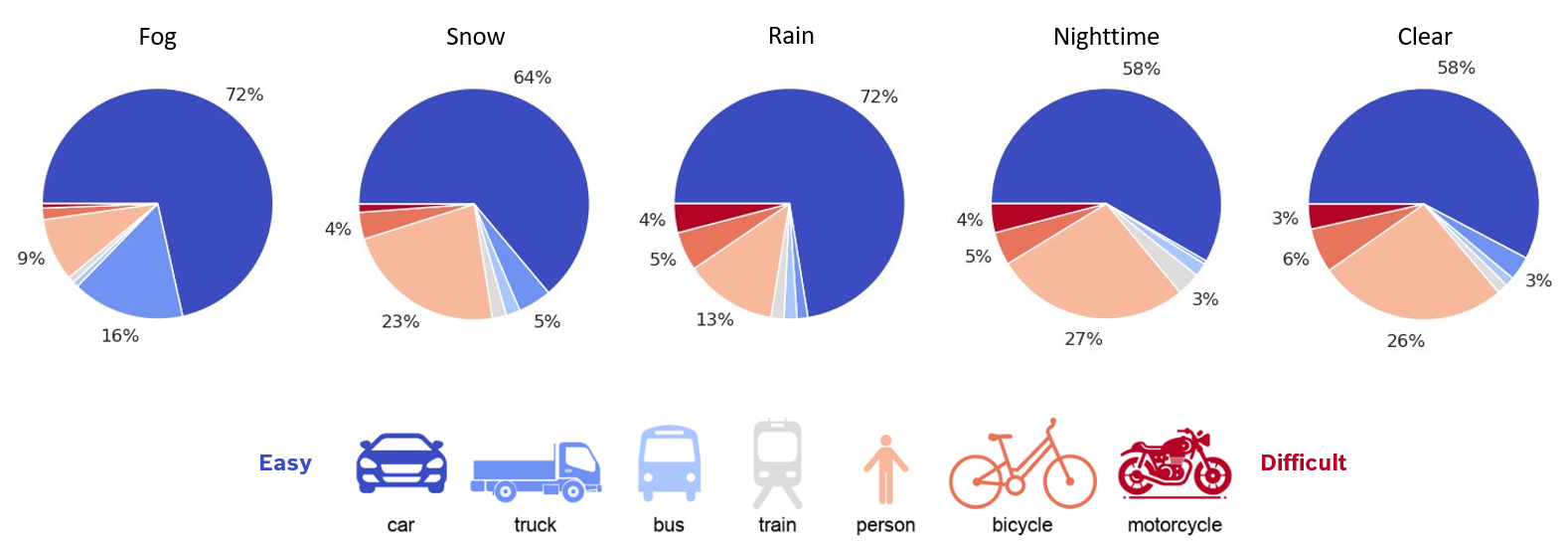
Figure: Object category distribution varies significantly across weather conditions, with clear and nighttime containing more difficult objects (e.g., bicycles, motorcycles).
Auxiliary Inputs Matter
Our enhanced DA-UNIT architecture accepts depth maps, semantic segmentation, and instance segmentation as auxiliary inputs. These inputs significantly improve object preservation during domain adaptation.
Different configurations of auxiliary inputs have distinctive effects on the generated images, with depth maps at the encoder stage providing the best balance of realism and object integrity.

Figure: Comparison of generation results with different auxiliary input types. Left column shows clear input, right columns show outputs with different auxiliary inputs.
Adaptive Blending Technique
Our novel blending approach addresses hallucinations and artifacts in diffusion outputs by adaptively combining the best parts of CARLA simulations with diffusion-enhanced regions.
We discovered that different object categories benefit from different blending weights: vehicles and traffic lights work best with low diffusion influence (0.1), while static background elements like roads benefit from higher diffusion influence (0.8).
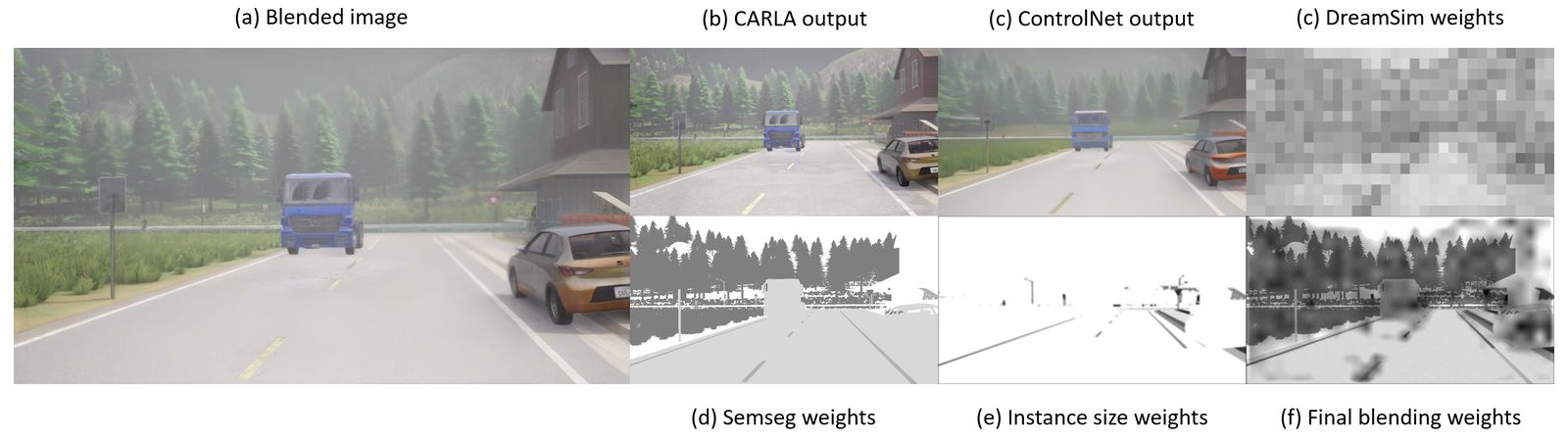
Figure: Our blending technique removes artifacts while preserving photorealism. Left to right: semantic segmentation, CARLA simulation, diffusion output, and final blended result.
Research Impact
Practical Applications
- Autonomous Driving: Enhances perception-system robustness across a wide range of adverse weather conditions.
- Task-Agnostic Data: Generated adverse-condition images can be reused for any downstream vision task (detection, segmentation, depth, etc.), not just semantic segmentation.
- Model Training: Introduces a domain-adaptation strategy that preserves both semantic labels and fine-grained details during style transfer.
- Industry Integration: A modular, plugin-style pipeline that can slot into existing autonomous-driving toolchains with minimal retraining.


